元PDFはこちらからダウンロードできます: http://newartisans.com/2008/04/git-from-the-bottom-up/
元記事のライセンスがクリエイティブコモンズのBY-SAであったため、この翻訳もBY-SAとなります。
ライセンスを守って自由にご利用ください。(詳しくは記事内の最初にも書いてあります)
翻訳ミスの指摘や改善の提案等があればブログコメントやTwitter(@oshow)などで遠慮なくどうぞ。
Git をボトムアップから理解する
Wed, 2 Dec 2009
by John Wiegley
by John Wiegley
私が Git を理解しようと調査した時、高級なコマンドの視点から眺めるよりボトムアップ式に理解することが役立った。そしてボトムアップ視点で見る Git がこんなにも美しくシンプルであるなら、私が調べたことを他の人も興味を持って読んでくれるのではないか、そうして私が経験した苦労を避けられるのではと考えた。
この文書にある例には、Git 1.5.4.5 を使用している。
目次
1. ライセンス
この文書は米国クリエイティブ・コモンズライセンス 3.0 の BY-SA 条件下で提供される。以下の URL を参照のこと:
要するに、著者情報が維持される限り、あなたはこの文書のコンテンツを個人目的、商業目的、その他のどんな目的にも利用できる。同様に、オリジナルの文書と同じ条件で頒布される限り、この文書の改変、派生作品の制作、翻訳は自由に行える。
(訳注:ということで、この翻訳も CC 3.0 の BY-SA で提供されます。すなわち、あなたはこの翻訳を上の条件で扱って良いということです。翻訳者名は O-Show でお願いします)
2. 導入
Git の世界へようこそ。本文書がこの強力なコンテンツ・トラッキングシステムをより理解するための助けになること、そしてその根底にあるちょっとしたシンプルさ――外側から見たら目眩がしそうなオプション群だけれど――を明らかにする助けになるのを願っている。
本題に入る前にまず、本稿中で繰り返し現れる、触れておくべき用語がいくつかある:
repository
リポジトリ (repository) はコミットの集合であり、各コミットはプロジェクトにおいて過去に存在したワーキングツリーのアーカイブだ。コミットは過去あなたのマシン上にあったのか、それとも他の誰かのマシン上にあったかは関係ない。またリポジトリは、現在のワーキングツリーがどのブランチまたはコミットから由来しているのかを特定する、HEAD (以下で触れる) というものを定義する。さらに、ブランチやタグという、コミットを名前で把握するためのものも含んでいる。
the index
あなたが使用してきたであろう他の似たツールと違い、Git はワーキングツリーからリポジトリへ変更を直接コミットしない。代わりに、変更はまずインデックス (index) と呼ばれる場所へ登録される。コミットする (あなたが承認した変更をいっぺんに全て記録する) 前に、一つずつ、あなたの変更を「確認する」方法だと考えるといい。インデックスと呼ぶ代わりに「ステージングエリア」と呼ぶほうが理解の助けになるかもしれない。
working tree
ワーキングツリー (working tree) は、それに関連するリポジトリを持った、ファイルシステム上のあるディレクトリのことだ (普通は中に .git という名前のサブディレクトリが存在することでわかる)。ワーキングツリーには全てのファイルとサブディレクトリが含まれている。
commit
コミットはある時点でのワーキングツリーのスナップショットだ。そのコミットをする時点の HEAD (以下で見る) の状態が、そのコミットの親になる。これこそが「リビジョン履歴」という概念を作成することにあたる。
branch
ブランチはコミットのただの別名であり (かつそれ以上に、ある時点のコミット群について述べるための物でもあるだろう)、またリファレンスとも呼ばれる。リポジトリの歴史を定義するコミットの系統図であり、従って「開発における枝分かれ」を表現する典型的概念である。
tag
タグもまたブランチと同様にコミットの別名であるが、常に同じコミットを指すということと、自身を説明するテキストを持ちうるという点が異なる。
master
ほとんどのリポジトリにおける開発のメインラインは 「master」 と呼ばれるブランチ上で行われる。通常これがデフォルトだが、決して特殊なブランチではない。
HEAD
HEAD は現在チェックアウトされているものを定義するために、リポジトリで使われる。
- もしブランチをチェックアウトしているなら、HEAD はそのブランチ (名) を指し、次のコミット操作の後ではその名前のブランチがアップデートされることを表す。
- もし特定のコミットをチェックアウトしているなら、HEAD はただそのコミットだけを指す。これは detached HEAD と呼ばれ、例えば、タグ名でチェックアウトするとそういうことが起こる。
Git における一般的な流れはこうだ。リポジトリを作成した後、あなたの作業はワーキングツリーで行われる。仕事が1段落したら――バグ修正が完了したり、労働時間の終わりだったり、全てのコンパイルが通った時などに――逐次変更をインデックスに追加する。コミットしたい全てのものがインデックスに追加されたら、その内容をリポジトリに記録する。通常のプロジェクトのライフサイクルを示す簡単な図は以下のとおりだ:

この基本的な構図を頭に置きながら (*1)、以下のセクションでは Git の操作においてこれらの各実体の違いが如何に重要かを説明したいと思う。
(*1) 本当は、チェックアウトはリポジトリからインデックスへのコピーを引き起こし、それからワーキングツリーへ書きだされる。しかしチェックアウト操作におけるこのインデックスの使われ方をまだ見ていないので、それは図の中であまり分かりやすい表現にならないと思った (ので省いた)。
3. リポジトリ:ディレクトリ内容の追跡
以上のように、Git がすることはかなり原始的だ。「ディレクトリのスナップショットを保全する」。この基本的なタスクを見ていくことで、多くの内部的デザインが理解可能だ。
Git リポジトリのデザインは様々な点で Unix ファイルシステムの構造を反映している。すなわち、ファイルシステムはルートディレクトリから始まり、ルート以下にはさらに他のディレクトリがあり、それらディレクトリのほとんどが葉となるノード、つまりファイル (これがデータを含んでいる) を持つ。これらのファイルの内容に関するメタデータとしては、まずディレクトリ名があり、さらに i-node というファイルの内容への参照 (ファイルサイズ、ファイルタイプ、権限) に保管される。各 i-node は関連するファイルの内容を識別する一意の数字を持つ。そして複数のディレクトリエントリがある特定の i-node を指すこともある (例:ハードリンク) 。ファイルシステム上に保存された内容を「所有している」のは i-node だと言えるだろう。
内部的に Git の構造は著しく Unix ファイルシステムに似ているものの、1・2個の主要な違いがある。第一に、ファイルの内容を blob というもので表現する。blob はまた、ディレクトリによく似た tree と呼ばれるものにとっての葉にあたるノードにもなる。ちょうど i-node が、システムが振った数字で一意に特定されるように、blob は自身のサイズと内容から計算される SHA-1 ハッシュによって名付けられる。これは i-node と同じくただの任意の数字だが、2つの追加的な特性がある。一つは、blob の内容が変更されていないことを証明する。もう一つは、同じ内容ならば常に同じ blob として表現される。それがどこに現れたとしてもだ。コミットをまたいでも、リポジトリをまたいでも――インターネット越しだとしても。もし複数の tree が同じ blob を参照していたら、これはまさにハードリンクに似ている。その blob は、少なくとも一つのリンクが残っている限り、あなたのリポジトリから削除されたりはしない。
Git の blob と、ファイルシステムにおけるファイルの違いは、blob は自身の内容についてのメタデータを一切保管しないことだ。そのような情報は全て、その blob を保持する tree の方が持つ。ある tree は、その blob の内容で "foo" という名前のファイルが 2004 年の 8 月に作成されたということを知っており、また他の tree は同じ内容が "bar" という名前で 5 年前に作成されたと知っているかもしれない。普通のファイルシステムでは、同じ内容だがそのような異なるメタデータを持つ2つのファイルは、常に2つの独立したファイルとして表現されるだろう。この違いはなぜだろう? 主として、ファイルシステムは変更されるファイルをサポートするようデザインされているが、Git はそうではないからだ。Git リポジトリではデータが不変 (immutable) であるという事実が、これら全ての動作と、そのような異なるデザイン要請を決めている。そして結局のところ、このデザインが遥かにコンパクトな収容力をもたらす。一意の内容を持つ全てのオブジェクトは、それがどこに位置していたとしても共有され得るからだ。
blobの紹介
基本的な構想は見えたので、いくつかの実例に入っていく。まずサンプルの Git リポジトリを作成する事から始め、そのリポジトリで Git がどのように動作するかをボトムアップからお見せするつもりだ。 以下、必要ならば適宜読み替えて欲しい。$ mkdir sample; cd sample $ echo 'Hello, world!' > greetingここではファイルシステム上に "sample" という名前の新しいディレクトリを作成し、そこに平凡な内容のファイルを入れた。まだリポジトリ作成すらしていないが、Git が何をしていくかを理解するために、もう Git コマンドを使い始めることもできる。まず、Git がどんなハッシュ ID を使って greeting というテキストを格納するのかを知りたいとしよう:
$ git hash-object greeting
af5626b4a114abcb82d63db7c8082c3c4756e51b
あなたのシステム上でこのコマンドを走らせたら、あなたの方も同じハッシュ ID が表示されるはずだ。私たちは2つの異なるリポジトリ (もしかしたら別世界に存在するかも) を作成しているのだが、2つのリポジトリ中の greeting blob は同じハッシュ ID を持つことになる。私はあなたのリポジトリから私の方へコミットを引っ張って来ることができるし、Git は私たちが同じ内容を追跡しているのだと気づくだろう――つまり1つのコピーだけが格納される! とてもクールだ。次のステップは、新しいリポジトリを初期化してそれにファイルをコミットすることだ。今はオールインワンのやり方でこれを実行するが、水面下で何が起っているか理解するため、またここへ戻ってくるつもりだ。
$ git init $ git add greeting $ git commit -m "Added my greeting"ここでのポイントは、blob はまさに私たちが期待するように、上記で決定されたハッシュ ID を持ってシステム上に保存されるということだ。また Git が必要とするハッシュ ID の桁数は、リポジトリ中でそれを一意に特定できる長さだけとなる。通常はたった 6 桁か 7 桁で充分だ:
$ git cat-file -t af5626b
blob
$ git cat-file blob af5626b
Hello, world!
そらきた! 私はあの blob がどのコミットに保持されているのかも、何の tree の中にあるかも調べていない。でも、仮定されていた唯一の情報 (ハッシュ ID) に基づいて、存在することが確認できた。リポジトリがどれだけ長く存在しても、ファイルがその中のどこに格納されていても、この blob は常に同じ識別子を持つだろう。これらの内容は、今や確認可能な形で保存されている。そう永遠にだ。
このように、blob は Git での基本的なデータ単位を表す。言ってみれば、Git の全てのシステムは blob を管理するためにあるのだ。
blob は tree が保管する
あなたのファイルの内容は blob に格納されるが、blob には何か特徴があるわけではない。blob は名前を持たず、構造も持たない――まさに「blob (カタマリ)」というわけだ。Git はファイルの構造と名前を表現するために、blob を tree へ葉ノードとしてくっつける。今のところちょっと見ただけでは、どの tree に目的の blob があるのかを見つけることはできない。多くの、とても多くの所有者 (tree) がいるかもしれないからだ。しかし、さっきの blob はたった今作ったコミットが保持する tree のどこかに必ず存在するはずだ:
$ git ls-tree HEAD
100644 blob af5626b4a114abcb82d63db7c8082c3c4756e51b greeting
そらきた! この最初のコミットは greeting ファイルをリポジトリへ追加したものだ。このコミットは、Git の tree を一つ含み、それはたった1つの葉を持つ。つまり greeting の内容を表す blob だ。ls-tree に HEAD を渡すことで、件の blob を含んだ tree があるということはわかったが、その HEAD コミットによって参照される実際の tree オブジェクトはまだ見ることができていない。以下のように、違う部分にライトを当てるコマンドならば tree オブジェクトを見つけられる:
$ git rev-parse HEAD 588483b99a46342501d99e3f10630cfc1219ea32 # これはあなたのシステム上では別物になる
$ git cat-file -t HEAD
commit
$ git cat-file commit HEAD
tree 0563f77d884e4f79ce95117e2d686d7d6e282887
author John Wiegley <johnw@newartisans.com> 1209512110 -0400
committer John Wiegley <johnw@newartisans.com> 1209512110 -0400
Added my greeting
最初のコマンドは HEAD というエイリアスをそれが参照するコミットへとデコードし、二番目のコマンドはオブジェクトの種類を確認する。三番目のコマンドはそのコミットが保持する tree のハッシュ ID を表示しているが、同様にコミットに格納された他の情報も見せている。コミットのハッシュ ID は私のリポジトリ特有のものだ――なぜならばそれは、私の名前と、コミットを作成した時の日付を含むからだ――しかし、tree のハッシュ ID はあなたの手元と私のものは共通であるはずだ。同じ内容の blob を同じ名前で保持しているのだから。これが本当に同じ tree オブジェクトであるということを確かめてみよう:
$ git ls-tree 0563f77
100644 blob af5626b4a114abcb82d63db7c8082c3c4756e51b greeting
以上、ご覧の通りだ。私のリポジトリはただ一つのコミットを含み、そのコミットは 1 個の blob を持つ 1 個の tree を参照している――blob は私が記録したい内容を含んでいる。これが本当にそうであるか確かめられるコマンドがもう一つある:
$ find .git/objects -type f | sort
.git/objects/05/63f77d884e4f79ce95117e2d686d7d6e282887
.git/objects/58/8483b99a46342501d99e3f10630cfc1219ea32
.git/objects/af/5626b4a114abcb82d63db7c8082c3c4756e51b
この出力からわかるのは、私のリポジトリは全体で3つのオブジェクトを含んでおり、それぞれが以前の例で現れたハッシュ ID を持っているということだ。好奇心を満たすために、最後にこれらのオブジェクトのタイプを調べてみよう:$ git cat-file -t 588483b99a46342501d99e3f10630cfc1219ea32 commit $ git cat-file -t 0563f77d884e4f79ce95117e2d686d7d6e282887 tree $ git cat-file -t af5626b4a114abcb82d63db7c8082c3c4756e51b blobこれらのオブジェクトのそれぞれの簡単な内容を見る git show コマンドを使うこともできたが、それは読者の練習のために残しておくこととしよう。
tree はどのように作られるか
あらゆるコミットが tree を1つは保持するが、tree はどのように作られるのだろうか? 私たちは blob が、ファイルの内容をその中へと詰め込むことで作成されるということを知っている――そして blob は tree に所有されることも知っている――わけだが、blob を保持する tree がどう作られるか、あるいは tree がその親となるコミットへどうリンクされるか、というのはまだ見たことがない。再び新しいサンプルリポジトリを始めよう。ただし、今度は手作業でだ。そうすれば裏側で何が起っているのか正確に掴むことができるだろう:
$ rm -fr greeting .git $ echo 'Hello, world!' > greeting $ git init $ git add greetingあなたが index へファイルを追加するとき、全ては始まる。さしあたり、index はファイルから blob を作成するために最初に使われるものだと思って欲しい。greeting ファイルを追加した時、リポジトリには変化が起っている。この変化はまだコミットとして見ることはできないが、何が起っているかを確認することはできる:
$ git log # これは失敗する。まだコミットは存在しない! fatal: bad default revision 'HEAD'
$ git ls-files --stage # index によって参照される blob を一覧表示する 100644 af5626b4a114abcb82d63db7c8082c3c4756e51b 0 greetingこれはなんだろう? 私はまだリポジトリへ何もコミットしていないが、オブジェクトが既に一つ生まれている。このオブジェクトは私がこの記事の始めでやったのと同じハッシュ ID を持っているから、きっと greeting ファイルの内容を表しているはずだ。この時点でハッシュ ID に対して cat-file -t を使うこともでき、そうしたらそれが blob であることもわかっただろう。実際それは、さっきのサンプルリポジトリを作ったときに最初に手に入れたと同じ物だ。同じファイルは常に同じ blob になる (万が一私が充分に伝えきれていなかった場合のために、もう一度強調しておこう)。
この blob はまだ tree によって参照されていないし、どのコミットにも属していない。現在、.git/index という名前のファイル (現在の index にまとめられている blob と tree を参照するファイル) から参照されているだけだ。なので、この中ぶらりの blob のために tree を作成しよう:
$ git write-tree # 一つの tree として index の内容を記録する 0563f77d884e4f79ce95117e2d686d7d6e282887この値は見たことがあるだろう。同じ blob (とサブtree) を含んだ tree は、常に同じハッシュ ID を持つ。まだコミットオブジェクトはないのだが、blob を保持した tree オブジェクトがもうリポジトリの中に存在している。低レベルの write-tree コマンドの目的は、index の内容を全て取り、コミットを作るために新しい tree の中へそれらを詰め込むことだ。
この tree を直接使用して、新しいコミットオブジェクトを手動で作成することができる。commit-tree コマンドを走らせるのだ:
$ echo "Initial commit" | git commit-tree 0563f77
5f1bc85745dcccce6121494fdd37658cb4ad441f
生の commit-tree コマンドは tree のハッシュ ID を取り、それを保持するコミットオブジェクトを作成する。もしコミットに親を持たせたかったら、-p オプションを使って、明示的に親のコミットのハッシュ ID を指定しなければならない。またここで注意することは、ハッシュ ID はあなたのシステム上に現れるものと異なるということだ。これは、私のコミットオブジェクトには私の名前とコミットを作成した日付が使われているからであり、これら二つの詳細は常にあなたのものとは違うはずだ。しかし、まだ作業は終っていない。現在のブランチの新しい HEAD としてそのコミットを登録していないからだ:
$ echo 5f1bc85745dcccce6121494fdd37658cb4ad441f > .git/refs/heads/masterこのコマンドは Git に「"master" という名前のブランチはさきほどの最新のコミットを指すようにしてくれ」と伝える。これとは別のもっと安全な方法は、update-ref コマンドを使うことだ:
$ git update-ref refs/heads/master 5f1bc857master を作成した後、それに対して私たちのワーキングツリーを関連付けなければならない。通常、これはブランチをチェックアウトした時はいつも起こることだ:
$ git symbolic-ref HEAD refs/heads/masterこのコマンドは master ブランチに対して、シンボリックに HEAD を関連付ける。これが重要で、なぜなら、ワーキングツリーからの将来のどのコミットも自動的に refs/heads/master の値を更新することになるからだ。
こんなに単純であるとは信じ難いのだが、もう私の真新しいコミットを見るために git log を使うことができる:
$ git log
commit 5f1bc85745dcccce6121494fdd37658cb4ad441f
Author: John Wiegley <johnw@newartisans.com>
Date: Mon Apr 14 11:14:58 2008 -0400
Initial commit
傍注:もし refs/heads/master が新しいコミットを指すように私がセットしなかったら、そのコミットは "unreachable (到達不可能)" になると考えられる。現在そのコミットを参照しているものが何もないし、到達可能なコミットの親でもないからだ。このような場合、コミットオブジェクトはそれが持つ tree と全ての blob と一緒に、いつかの時点でリポジトリから削除されるだろう (これは git gc と呼ばれるコマンドによって自動的に行われ、あなたが手でやることは滅多にない)。refs/heads の中に名前をリンクさせたコミット、つまり上でやったようものは reachable (到達可能) なコミットになるので、その時点からリポジトリに保管されることが確実になる。
コミットの美
いくつかのバージョン管理システムでは "ブランチ" を特別なものとして作成し、しばしば "メインライン" や "trunk" といったものからはっきり区別する。またブランチはまるでコミットとは非常に異なるものであるかのようにその概念を議論する。しかし、Git ではブランチは異なった実体として存在するわけではない。ただ blob、tree、そしてコミット (*2) があるだけだ。コミットは一つ以上の親を持てるし、それらの親コミットも親を持てるので、これはある単独のコミットがブランチのように扱われることを許可する。なぜならばそれは、そこに至るまでの全ての履歴を知っているからだ。(*2) ああ、Git にはタグもあるが、これはただのコミットへの参照であり、ここでは無視する。
あなたは branch コマンドを使うことで、いつでも、一番最新として参照されているコミットを調べることができる:
$ git branch -v
* master 5f1bc85 Initial commit
さあご一緒に。「ブランチはコミットに対する参照名以外の何者でもない」。このように、ブランチとタグは (タグの方は自身についての説明を持つことができるということだけを除いて) 同一であり、まさにそれらは参照されるコミットだ。ブランチはただの名前だが、タグは説明的だ…そう、”タグ” なのだ。だが本来は、私たちはエイリアスを使う必要は全くない。例えば、もしそうしたいなら、コミットのハッシュ ID だけを使ってリポジトリ内の全てを参照できる。さて試しに、指定したコミットへワーキングツリーをセットしなおしてみよう:
$ git reset --hard 5f1bc85--hard オプションはワーキングツリーの現在の全ての変更内容を、それが次のコミットのために登録されているかどうかに関係なく、消去する (このコマンドについては後でより詳しく触れる)。同じことをするもっと安全な方法としては、git checkout がある:
$ git checkout 5f1bc85ここでの違いは、ワーキングツリーの変更されたファイルは保護されることだ。もし checkout コマンドに -f オプションを渡したら、reset --hard をしたのと同じことになる。ただし、checkout がワーキングツリーだけを変更するのに対して、reset --hard は現在のブランチの HEAD を、指定したバージョンの tree を参照するように変更する、という点を除けば。
コミットベースのシステムの他の嬉しさは、最も複雑なバージョン管理の用語でさえ、一つの語彙を使って言い直すことができることだ。例えば、コミットが複数の親を持つなら、それは "マージコミット" だ――複数のコミットを一つのコミットへマージしたのだから。あるいは、あるコミットが複数の子を持つなら、それは "branch" の祖先であることを表す、など。実際、こういうものと Git の間には違いがない。つまり Git では、世界はシンプルなコミットオブジェクトの集合であり、それぞれのコミットオブジェクトが他の tree や blob を参照する tree を保持し、blob にはデータが保管されている。これよりも複雑な全ては、単に用語的な飾りにすぎない。
ここに、これら全てのピースがどう組合わさるかの図がある:

コミットを別名で言うと...
コミットを理解することは Git を理解する鍵だ。あなたの心がコミットのトポロジをただ受容する時、ブランチ、タグ、ローカル&リモートリポジトリ等の混乱は置き去りにされ、あなたは叡智ある禅・ブランチングの地平へと達したのを知るだろう。願わくばその体験があなたの腕を切り落とす (*3) 必要がないことを――もし今頃それを考えていたならば、だけれども。(*3) 参照:密教僧の恵果(空海の師)のエピソードより。
コミットが鍵ならば、コミットの指定方法を把握することが熟達への入り口だ。コミットの呼び方にはたくさんの、本当にたくさんの方法があり、コミットの範囲や、コミットによって保持されるオブジェクトさえも Git コマンドのほとんどで受け付けられる。基本以上の使い方の一覧を見てみよう:
ブランチ名
以前述べたように、どのブランチ名も "branch" 上の最新コミットへの単なるエイリアスにすぎない。そのブランチがチェックアウトされているなら、これは HEAD という単語を使うのと同じである。
タグ名
タグ名というエイリアスは、コミットの呼び名であるという観点からはブランチ名と同一だ。二つの間の主要な違いは、タグのエイリアス先は変わることがないのに対して、ブランチのエイリアス先はそのブランチで新しいコミットが作られる度に変わるということだ。
HEAD
現在チェックアウトされているコミットは常に HEAD と呼ばれる。もし特定のコミットを――ブランチ名を使う代わりに――チェックアウトしたら、HEAD はそのコミットだけを指し、現在どのブランチ上にもいないという状態になる。注意すべきはこのケースは特別なものであり、"using a detached HEAD (孤立した HEAD を使っています)" と言われてしまう。(きっといつもこれで言われているジョークがある…)
(訳注:detached HEAD = 頭がちょんぎれた! というジョークでしょうか?)
c82a22c39cbc32...
コミットは完全な 40 文字の SHA1 ハッシュ ID を使って常に参照され得る。同じコミットを指すのならもっと他の便利な方法があるので、これは普通カットアンドペーストする時に使われる。
c82a22c
ハッシュ ID でコミットを指定するなら、リポジトリ中でそれが唯一だと参照できるだけの桁を使う必要がある。たいてい、6文字か7文字あれば充分だ。
name^
キャレット文字を使うことで、コミットの親コミットが参照される。もしコミットが2つ以上の親を持つならば、最初のものが使われる。
name^^
複数のキャレットを用いることもできる。このエイリアスは、与えられたコミット名の「親の親」を表す。
name^2
もし複数の親を持つコミット (マージコミットのような) ならば、name^N を使って N 番目の親を参照できる。
name~10
あるコミットの N 番目の祖先は、チルダ (~) のあとにその順番の数を加えたものを使うことで参照される。この用法は rebase -i において一般的だ。例えば、「最新のコミットたちを見せて欲しい」という意味で使える。また、これは name^^^^^^^^^^ と同じになる。
name:path
コミットが持つファイルツリー中のとあるファイルを参照するために、コロンの後にファイル名を指定できる。これは git show、あるいは2つのコミット間でファイル差分を見るのに役立つ:
$ git diff HEAD^1:Makefile HEAD^2:Makefile
name^{tree}
コミット自身ではなく、そのコミットが持つ tree の方を参照できる。
name1..name2
これ以降のエイリアスはコミットの範囲を示す。コミット範囲は、特定の期間のあいだで何が起こったかを見るための git log のようなコマンドでこの上なく役に立つ。
上の構文は name2 から name1 までの到達可能な全てのコミットを表すが、name1 (が指すコミット) を含まない。もし name1 か name2 が省略されたら、そこには HEAD が使用される。
name1...name2
"3ドット"の範囲は上記の2ドットバージョンとかなり違う。git log のようなコマンドでは、name1 だけ、あるいは name2 だけから参照される全てのコミットを表すが、両方から参照されるコミットは表さない。結果として (name がブランチだとすると) 両方のブランチでユニークな全てのコミットをリストすることになる。
git diff のようなコマンドでは、表現される範囲は「name2」と「name1 と name2 の共通の祖先」の間になる。これは、git log では name1 で導入された変更が表示されないのと異なる。
master..
この用法は "master..HEAD" と同等だ。さきほどの用法にも含まれていたが、あえてここでも例として追加した。なぜならば、現在のブランチで作成した変更をレビューするときに、この種のエイリアスを頻繁に使用するからだ。
..master
これもだ。git fetch し終わって、最後にした rebase あるいは merge からどんな変更が起こったかを見たい時に特に役立つ。
--since="2 weeks ago"
指定日からの全てのコミットを指す。
--until=”1 week ago”
指定日までの全てのコミットを指す。
--grep=pattern
コミットメッセージが正規表現パターンにマッチする全てのコミットを指す。
--committer=pattern
コミッタ (コミットをした人) がパターンにマッチする全てのコミットを指す。
--author=pattern
author がパターンにマッチする全てのコミットを指す。コミットの author とは、そのコミットの変更を作成した人のことだ。ローカルな開発ではこれは常にコミッタと同じになるが、パッチが e-mail で送られている時は、author とコミッタは普通別になる。
--no-merges
指定した範囲中で、ただ一つだけの親を持つ全てのコミットを指す――すなわち、全てのマージコミットを無視する。
これらのオプションの大半は、混ぜたりかけ合わせたりできる。ここに、以下で説明するログエントリを表示する例を示す。現在のブランチでの変更 (ブランチは master から派生している) で、かつ自分が変更したもので、過去一ヶ月の間の、"foo"というテキストをコミットメッセージに含むもの。すると以下になる。
$ git log --grep='foo' --author='johnw' --since="1 month ago" master..
ブランチングと rebase の力
コミットを操作するための最も有能な Git コマンドは、無邪気にも名付けられた rebase コマンドだ。基本的に、あなたが作業をするブランチは全て、一つ以上の「ベースコミット」を持っている。ブランチがそこで生まれたコミットのことだ。例として、以下のよくあるシナリオを見ていこう。注意しておくと、矢印は過去を遡って指している。なぜならば各コミットはその親を参照しているのであって、子ではないからだ。したがって、D と Z のコミットがそれぞれのブランチの HEAD を表している:
この場合、稼働中のブランチは2つの「ヘッド」を示している。D と Z、両方のブランチが A という共通の親を持つ。git show-branch の出力がまさにこの情報を見せてくれる:
$ git branch
Z
* D
$ git show-branch
! [Z] Z
* [D] D
--
* [D] D
* [D^] C
* [D~2] B
+ [Z] Z
+ [Z^] Y
+ [Z~2] X
+ [Z~3] W
+* [D~3] A
この出力を読むには少しの慣れが必要だが、本質的には上記の図と変わるところはない。ここでは、以下のようなことを伝えている:
- ブランチが最初の分岐を体験したのはコミット A の時だ (またそれは D~3 として知られていて、そして、あなたがそう思うなら Z~4 とも言える)。コミット^ という構文はコミットの親を指すのに使われ、コミット~3 は3つ上の親、または曾祖父を指す。
- これは下から上に読んで行く。最初の列 (+の印) は Z という名前のブランチが分岐したことを示していて、それは4つのコミットを持つ。W、X、Y、そして Z だ。
- 二番目の列 (アスタリスクの印) は現在のブランチで発生したコミットを示す。すなわち3つのコミットの B、C、そして D だ。
- 出力の一番上、線で区切られることで下部と分離している部分は、表示されるブランチたちを識別する。ブランチにラベルされている印が、そのブランチに属するコミットへとラベルづけされるように列が配置されている。
他のバージョン管理システムでは、この手のことは「ブランチのマージ」を使用して済ます事になる。実際、ブランチのマージは Git でも実行可能だ。マージの使用は、Z が 公開されたブランチであり、そのコミット履歴を変えたくないという場合には、今も必要とされる。実行するコマンドはこうだ:
$ git checkout Z # Z ブランチへ切り替え $ git merge D # B、C、Dのコミットを Z へマージ
これがその後のリポジトリの状態だ:

いま Z ブランチをチェックアウトするなら、それは以前の Z (現在は Z^ として指す) の内容に、D の内容をマージしたものが含まれているだろう。(注意:実際のマージ操作では、D と Z の状態の間の全ての衝突を解決している必要がある)
新しい Z ブランチは現在 D からの変更を含んでいるが、Z と D をマージしたことを表す新しいコミットも含んでいる。そのコミットは今 Z' として表示されている。これは何も新しいものを追加しないコミットだが、D と Z をまとめる操作を終えたことを表す。ある意味ではそれは「メタコミット」と言える。なぜならばその内容は単にリポジトリ中で作業したことに関係していて、ワーキングツリーには何も新しいことをしていないからだ。
しかしながら、Z ブランチをそのまま D の上に移植し、Z が前方になるよういっぺんに移動させてしまう方法がある。パワフルな rebase コマンドを使うのだ。ここに、私たちが目指す図がある:

この状態は最も直接に私たちがしたいことを表している。私たちのローカルリポジトリでは、開発ブランチの Z がメインブランチ D の最新の仕事に基づくようになる。なぜ「rebase」とそのコマンドが呼ばれるのかは、それが指定したブランチのベースになるコミットを変更するからだ。もしあなたがそれを毎回のように走らせるなら、ワーキングブランチ上のパッチたちを制限なく前に進ませ、常にメインブランチと共に最新の状態に置くことができる。しかも、開発ブランチへ不必要なマージコミットを追加しなくて済む (*4)。ここでは、上で実行したマージ操作と比較できるよう、コマンドを実行している:
$ git checkout Z # Z ブランチへ切り替える $ git rebase D # Z のベースコミットを D の地点へ変更する
これがなぜローカルブランチのためだけなのだろう? なぜならあなたが rebase をする度に、ブランチ内の全てのコミットを潜在的に変更してしまうからだ。以前に、W が A を分岐元にしていた時、それは A から W へ内容を変化させるために必要な変更だけを含んでいた。しかしながら、rebase が 走ったあとは、W は D から W' へ内容を変化させるために必要な変更を含むように書き換えられてしまう。そして W から X への内容の変化すらも変更されてしまう。なぜならば A+W+X は現在 D+W'+X' だからだ――Y 以降も同じだ。もしこれが、ブランチの変更が他の人々に見られているならば、そしてあなたの下流の利用者の誰かが Z から分岐した彼ら自身のローカルブランチを作成しているならば、彼らのブランチは今、新しい Z' ではなく古い Z を指しているだろう。
一般に、以下の経験則が利用できる。もしそこから他のブランチが分岐したことがないようなローカルブランチを持っているなら、rebase を使い、その他の全てのケースでは merge を使う。あなたのローカルブランチの変更をメインブランチへ pull し戻す用意が出来ているときも、merge は役に立つ。
(*4) これを使用しない、そして代わりにマージを使う正当な理由が存在することに注意しよう。選択はあなたの状況に依存する。rebase の一つの悪い面は、rebase されたワーキングツリーはコンパイルに通っても、中間のコミットのコンパイルが通るかはもはや何の保証もないということだ。新しい rebase された状態でそれらがコンパイルされたことはないからだ。歴史的正当性があなたにとって重要なら、merge を好んで使うこと。(訳注:これに対する反論→【翻訳】Rebaseは安全である)
対話的リベース
上記のように rebase が実行されたとき、Z ブランチを D コミット (すなわち、D ブランチの HEAD) の上へリベースするために、W から Z までの全てのコミットが自動的に書き換えられる。しかし、どのように書き換えが行われるかをあなたが完全に取り仕切ることもできる。rebase に -i オプションを与えると、Z ローカルブランチ内のコミット毎に何が行われるかを選択するための編集バッファが開くことになる:pick
これは、あなたが対話的モードを使わなかった場合の、ブランチ内の各コミットへ選択されるデフォルトの振る舞いだ。当該コミットは自身 (今書き換えられている) の親コミットへ再適用されることを意味する。発生したコンフリクトに関係するコミット毎に、rebase コマンドはあなたにそれらを解決する機会を与える。
squash
squash を指定されたコミットは、自身の内容を、それの一つ前のコミットの内容の中へ「折り込まれる」ことになる。これは何回でも行われる場合がある。もし上記の例のブランチを対象に、全てのコミットを squash にしたら (一番目のコミットは除く。そのコミットは squash されるために pick でなければならない)、新しい Z ブランチはただ一つだけのコミットを含んで、D の上へ追加されることになる。あなたが複数のコミットに渡って変更をばらまいているが、それら全てを一つのコミットに見せるように履歴を書き換えたいならば、これは役に立つ。
edit
edit としてコミットをマークすると、rebase のプロセスはそのコミットの所で停止し、そのコミットを反映したワーキングツリーと共に、シェルがあなたの元に残される。その時 index は、あなたがそのコミットを作成する際に登録された変更を全て含んでいる。従ってあなたはなんでもしたいように変更できる。変更のやり直し、変更を元に戻す、その他。そしてコミットをした後、rebase --continue を走らせると、そのコミットはまるで元からそういう変更だったかのように書き換えられる。
(drop)
もし対話的リベース時の編集バッファ中の一覧からコミットを削除する、あるいはコメントアウトするなら、そのコミットは単にまるでチェックインされていなかったかのように見えなくなる。ブランチ内の後ろのコミットがそれらの変更に依存していたとしたら、これはマージの衝突を起こしうることに注意すること。
このコマンドのパワーは最初理解しにくいのだが、それはあなたにどんなブランチの形をも、事実上無制限にコントロールすることを許可する。これは以下のことに使用できる:
- 複数のコミットを一つのコミットにまとめる。
- コミットの順番を変える。
- 現在は後悔している正しくない変更を取り除く。
- ブランチのベースを、リポジトリ中の他のコミットへ移す。
- あるコミットを、コミットしてだいぶ後になってから訂正する。

この図を見てみると、開発のメインラインとして D があり、その3つ前のコミットから試作開発のための Z ブランチが分岐している。これら両方の真ん中の地点、C と X がそれぞれのブランチの HEAD だったとき、最終的に L となる他の試作ブランチを開始することを決めた。現在、L のコードが良い感じだとわかったが、メインラインへマージし戻すほどにはあまり良くない。なのでそれらの変更を Z 開発ブランチへ移動させることに決め、結局そこでやった全ての事が一つのブランチになるようにする。ああ、そして今それをやろうって時に、コミット J のコピーライトの日付をすぐにでも編集したくなった。私たちがその変更を作成したとき、2008年のままだったのを忘れていたからだ! この絡まりをほどくのに必要なコマンドはこうだ:
$ git checkout L $ git rebase -i Z発生する全ての衝突を解決したら、現在はこのようなリポジトリになる:
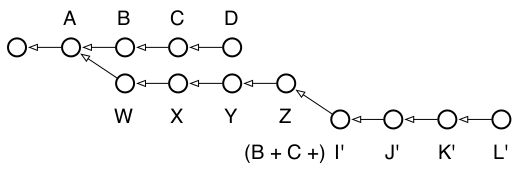
お分かりのように、ローカル開発での話ならば、rebase はあなたのコミットがどのようにリポジトリに現れるかを無制限にコントロールする力を与えてくれる。
4. インデックス:仲介者を知ろう
ファイルシステム上に保管されているデータファイルと、リポジトリに保管されている Git の blob の間には、なにやら奇妙な存在が立ちはだかっている。Git のインデックスだ。コイツを理解することを困難にしている部分は、それが不運な名前を持っているということだろう。新しく作成された tree や blob のセット (git add を実行した時に作成される) を参照するという意味では、これは index と言える。これら新しいオブジェクトは、あなたのリポジトリへコミットするという目的で、新しい tree へすぐにまとめられるだろう――だがその時まで、それらは index にだけ参照される。もし git reset によって index から変更を取り外すと、未来のいつかの時点で削除される孤立した blob を持つことになる。
index はただ本当に、次のコミットのためのステージングエリアであり、それがなぜ存在するかの良い理由もある。それは CVS や Subversion ユーザにとって慣れないかもしれないが、Darcs ユーザにとっては全くもって身近な開発モデルをサポートする。ステージで次のコミットを組み立てる能力だ。

まず最初に、index をほぼ完全に無視する方法があると言わせて欲しい。つまり git commit に -a フラグを渡すのだ。例えば Subversion で作業する方法を考えてみよう。svn status と タイプする時、あなたが見ることになるのは、次の svn commit の呼び出しであなたのリポジトリに適用されるだろうアクションのリストだ。ある意味で、この「次のアクションのリスト」は一種の非公式の index で、ワーキングツリーの状態と HEAD の状態を比べることで決定される。もし foo.c というファイルが変更されているならば、次のコミットでそれらの変更が保存されるだろう。もしある未知のファイルの横にクエスチョンマークがあれば、それは無視される。しかし、svn add で追加された新しいファイルは、リポジトリに追加されることになる。
これは git commit -a を使った場合に起こる事と違いがない。新しい、未知のファイルは無視されるが、git add で追加された新しいファイルなら、ファイルにしたどんな変更もリポジトリに追加される。この作用は Subversion が実行するやり方とほとんど同じだ。
本当の違いは、Subversion の場合では、あなたの「次のアクションのリスト」は常に現在のワーキングツリーを見て決定されるということだ。Git では、「次のアクションのリスト」は index の内容であり、次の HEAD の状態になるであろうものを表現し、そしてコミットを実行する前に直接操作することができる。これは、前もってその変更をステージさせてくれることによって、何が起きるかについてコントロールする追加のレイヤーを与えてくれるということだ。
まだ理解がクリアでないなら、以下の例について考えてみよう。あなたは信頼できるソースファイル、foo.c を持ち、それに対して無関係の二つのセットの変更を行なった。あなたがしたいことは、それらの変更を分割して二つの異なるコミットにし、それぞれに別の説明をつけたい。Subversion なら、これについてあなたがするだろう事はこうだ:
$ svn diff foo.c > foo.patch $ vi foo.patch $ patch -p1 -R < foo.patch # 二番目の変更セットを取り除く $ svn commit -m "First commit message" $ patch -p1 < foo.patch # 残りの変更を再適用する $ svn commit -m "Second commit message"これが楽しく感じる? なら今度は複雑かつ動的な変更のセットで複数回繰り返してみることだ。次は Gitで、index を使った方法だ:
$ git add --patch foo.c $ git commit -m "First commit message" $ git add foo.c # 残りの変更を add する $ git commit -m "Second commit message"その上、これはもっと簡単にできるのだ! もしあなたが Emacs が好きなら、Christian Neukirchan 作の最上級のツール gitsum.el (*5) がこの退屈なプロセスを美しくしてくれる。私は最近それを使って、合成されてしまっている変更を11の別のコミットへ分離した。ありがとう、Christian!
(*5) http://chneukirchen.org/blog/archive/2008/02/introducing-gitsum.html
一歩先のインデックス
なになに、index だって…。それがあれば変更のセットを事前ステージングでき、したがって、それをリポジトリへコミットする前に繰り返しパッチを組み上げることができるのか。さて、そんなコンセプトを以前もどこかで聞いたような…。「Quilt!」と考えているなら、あなたはまさに正しい。実際、index は Quilt (*6) と少ししか違わない。index の方は、一度にただ一つだけのパッチが構築されるという制限が追加されているだけだ。
(*6) http://savannah.nongnu.org/projects/quilt
しかし、さっきの foo.c の中に2セットの変更があるのではなく4セットあったらどうなる? プレーンな Git では、一つ解きほぐしてコミットし、そしてまた次のを解きほぐす、としなければならないだろう。index を使えばこれははるかに簡単になるが、それらをコミットする前に、それらの変更の各々を様々な組み合わせでテストしたいとしたらどうする? すなわち、パッチに A、B、C、D とラベル付けしたとして、どの変更が本当に正しいものか決める前に、A+B でテストし、次が A+C、次がA+D…というようにテストしたいとしたら?
複数の変更を休みなく選んで組み合わせるような仕組みは、Git 自身には存在しない。もちろん、複数ブランチはあなたに並行的な開発をさせることができるし、index は複数の変更を一連のコミットになるようステージングさせてくれるが、その二つを一度にすることはできない。一連のパッチを、その中から同時に使用・不使用を抜粋してステージングし、最終的にそれらをコミットする前に、一斉にパッチの統合を検証すること、をだ。
あなたがこういった事をするのに必要なものは、一度に1コミットするよりも深みのある index だろう。これはまさに Stacked Git (*7) が提供するものだ。
(*7) http://procode.org/stgit
以下は、素の Git を使ってワーキングツリーの中で2つの異なるパッチをコミットする時のやり方だ:
$ git add -i # 最初の変更セットを選択する $ git commit -m "First commit message" $ git add -i # 二番目の変更セットを選択する $ git commit -m "Second commit message"これはうまく動作するが、二番目のコミットを単独でテストする目的で一番目のコミットを選択的に適用しない、ということができない。以下のようにしなければならないだろう:
$ git log # 一番目のコミットのハッシュIDを見つける $ git checkout -b work <最初のコミットのハッシュ ID>^ $ git cherry-pick <2番目のコミットのハッシュ ID> $ git checkout master # master ブランチへ戻る $ git branch -D work # 一時的なブランチを削除する明らかに、もっといい方法があるはずだ! stg コマンドがあれば、両方のパッチをキューに入れ、好きな順番でそれらを再適用でき、単独または組み合わせてのテストをしたりできる。以下で stg コマンドを使って、前の例で利用した同じ二つのパッチをキューに入れている:
$ stg new patch1 $ git add -i # 一番目の変更セットを選択 $ stg refresh --index $ stg new patch2 $ git add -i # 二番目の変更セットを選択 $ stg refresh --index今、二番目だけをテストするために一番目のパッチを選択的に非適用状態にしたいとする。それは非常に簡単だ:
$ stg applied patch1 patch2 $ stg pop patch1 $ stg pop patch2 $ stg push patch1 $ stg push -a $ stg commit -a # 全てのパッチをコミットするこれは、一時的なブランチを作り、コミットのハッシュ ID を指定して cherry-pick を適用するよりも確実に簡単だ。
5. リセットすること、またはリセットしないこと
Git の中でマスターすることがより難しいコマンドの一つが、git reset だ。それは他のコマンドよりも使用者に噛み付きがちのように思える。名前から理解できるように、それはワーキングツリーと、HEAD の参照の両方を潜在的に変更してしまえる。なので、このコマンドの簡単なレビューが役立つだろうと思う。
そもそも git reset は「参照エディタ」であり、「index エディタ」であり、「ワーキングツリーエディタ」だ。とてもたくさんの仕事をする能力があることが混乱の一因になっている。これら3つのモードの間の違いを調査し、そして Git のコミットのモデルの中にそれらがどうフィットするかを調べてみよう。
mixed reset の実行
もし --mixed オプションを使うなら (あるいは、これがデフォルトなので、何もオプションをつけないなら)、git reset は与えられたコミットにマッチするように HEAD の参照を切り替えるとともに、index の部分を取り消すだろう。--soft オプションとの主な違いは、--soft では HEAD の 意味だけを変更し、index には何も触らないことだ。$ git add foo.c # 新しい blob として index へ変更を追加する $ git reset HEAD # index にステージされた全ての変更を削除する $ git add foo.c # 間違えていたので add をやり直し
soft reset の実行
git reset で --soft オプションを使うと、異なるコミットへ HEAD の参照を単に変更する (そこは先ほどの効果と同じだ)。ワーキングツリーでやった変更は、触れられずに残される。これは、以下の2つのコマンドが同等ということを意味する:$ git reset --soft HEAD^ # 自身の親へ HEAD を戻す。最後のコミットを事実上無視することになる $ git update-ref HEAD HEAD^ # 手動ではあるが、同じことをするどっちの場合でも、現在のワーキングツリーはより古い HEAD の上に存在するので、もし git status を走らせたら多くの変更が見えることになる。あなたのファイルは変更されてはおらず、単にそれらは現在古いバージョンと比較されているということだ。この状況は古いコミットを置き換えるように新しいコミットを作成するチャンスを与えてくれる。実際には、あなたが変更したいと思うコミットがもっとも最後にコミットされたものならば、あなたは最後のコミットに対して最新の変更を追加するために git commit --amend を使うこともできる。まるでそれらを一緒にコミットしていたかのようにね。
しかし、以下に注意しよう。あなたの下流に作業者がいて、その人たちがあなたの以前の HEAD――もう捨ててしまったものだ――を元に作業をしていたら、このような HEAD の変更は、その人たちの次の pull の後で、自動的な強制マージを引き起こす。以下は soft reset してから新しいコミットをした後、こうなるだろうというコミット履歴だ:

そしてこっちが、下流の作業者が再び pull をした後の彼らの HEAD がこうなるだろうという図だ (同色のコミットが同じものを意味している):

hard reset の実行
hard reset (--hard オプション) は非常に危険である可能性がある。一度に二つの異なることができるからだ。最初の例として、現在の HEAD に対して hard reset を行うなら、ワーキングツリー内の全ての変更が消去され、ワーキングツリーのファイルが HEAD の内容と一致するようになる。こういう事をするなら、もう一つ別のコマンドがある。git checkout だ。それは index が空ならば、git reset --hard とほぼ似た操作をする。そうでないなら、ワーキングツリーを index と一致させる。
次の例として、もっと以前のコミットに対して hard reset をしたならば、まず最初に soft reset をしてから、git reset --hard を使ってワーキングツリーをリセットしたのと同じになる。したがって、以下のコマンドは同等だ:
$ git reset --hard HEAD~3 # 変更を捨てて、過去に遡る $ git reset --soft HEAD~3 # 以前のコミットをHEADが指すようにする $ git reset --hard # ワーキングツリー内の差異を消し去るお分かりのように、hard reset を行うことは非常に破壊的になりうる。幸い、同じ効果を達成するもっと安全な方法として、Git では stash (次のセクションで見る) を使った方法が存在する:
$ git stash
$ git checkout -b new-branch HEAD~3 # head を遡る!
あなたがたった今現在のブランチを本当に修正したいのかどうか確信できないというならば、このアプローチには二つの異なる利点がある:- stash へあなたの仕事を保存する。そして、いつでもそこに戻ることができる。注意としては、stash は各ブランチ固有のものではないから、あるブランチのツリーの状態を stash して、後でそれを他のブランチに適用してしまう可能性もある。
- 過去の状態へワーキングツリーを巻き戻すが、新しいブランチ上で過去の状態に対して変更をコミットすると決めたならば、あなたのオリジナルブランチは維持されたままになるだろう。
$ git branch -D master # さようなら古い master(まだ reflog には、いる) $ git branch -m new-branch master # 今や new-branch が master になる
この話の教訓は以下のとおりだ。あなたは現在のブランチ上で git reset --soft や git reset --hard (ワーキングツリーも変更する) を使って一大手術をすることもできるが、なぜそんなことをしたいのだろうか? Git はとても簡単で安くブランチで作業させてくれる。(新しく作った) あるブランチ上で破壊的な修正をし、それから古い master の代わりとしてそのブランチを使うようにするのは、常に価値のあることだ。それはまるでフォースの暗黒面のような魅力を持っている…。
それから、あなたが誤って git reset --hard を走らせ、現在の変更を失うだけでなく、master ブランチから積み重ねたコミットまでも削除してしまったらどうなるだろう? そうなのだ、git stash を使ってスナップショットを取る (次のセクションで見る) という癖をつけていなかったのなら、失ったワーキングツリーを復活させる方法はない。しかし reflog (これも次のセクションで説明される) と共に git reset --hard を再び用いれば、ブランチだけは以前の状態へ復帰させることができる:
$ git reset --hard HEAD@{1} # reflog から変更前の状態へ復帰させる安全策でいくなら、必ず git stash を最初に走らせてから git reset --hard を使うことだ。これは後になってあなたの白髪が増えるのを防ぐだろう。git stash を走らせたなら、ワーキングツリーの変更を復帰させることにそれを使うことができる:
$ git stash # これをするのが常に良いことなので、とりあえずする $ git reset --hard HEAD~3 # 以前へ遡る $ git reset --hard HEAD@{1} # おっと、あれは間違いだった、やり直し! $ git stash apply # そしてワーキングツリーの変更を呼び戻す
6. 鎖をつなぐ最後の輪: stash と reflog
今までで、Git の中へ blob を送り込む2段階の方法を説明してきた。blob はまず最初に index に作成され、そこではまだ親 tree と所属するコミットがない。それからリポジトリへとコミットされ、コミットが保持する tree にぶら下がる葉として存在することになる。しかし、blob をリポジトリ内へ置くことができる方法が他にもまだ2つ存在する。
それらの内の最初の1つが Git の reflog であり、あなたがリポジトリにやった全ての変更を――コミット群の形で――記録するある種のメタリポジトリだ。これは、あなたが git commit を使って index から tree を作成しコミットとして保存したとき、そのコミットは reflog へもいつの間にか追加されることを意味する。reflog は以下のコマンドを使って確認することができる:
$ git reflog
5f1bc85... HEAD@{0}: commit (initial): Initial commit
reflog の美しいところは、リポジトリのその他の変更から独立して維持されているということだ。これは、私が上記のコミットを (git reset を使って) リポジトリのどこからもリンクされないようにしても、reflog からは30日間はいまだ参照され続け、ガーベジコレクションから守られることを意味する。コミットが本当は必要だったことがわかった場合に、これがあれば一ヶ月間はそれを取り戻すチャンスを与えてくれることになる。blob が存在できる他の場所は、間接的ではあるが、ワーキングツリー自身もそうだ。その意味する所は次のとおりだ。あなたが foo.c ファイルを変更したとして、だがまだ index にそれを追加していないとしよう。Git はあなたのために blob を作成しないだろうが、それらの変更は確かに存在し、blob に変換できる内容が存在することを意味する――Git リポジトリの代わりにファイルシステム中に置かれているわけだ。実際の blob が存在しないにも関わらず、ファイル自身は SHA-1 ハッシュ ID も持っている。それをこのコマンドで見ることができる:
$ git hash-object foo.c
<some hash id>
この事はあなたのために何をしてくれるだろう? さて、もしあなたがワーキングツリーにハックをやり込んで、長い一日の終わりに到達したら、身につけるべき良い習慣は、変更をしまい込むことだ:$ git stashこれはあなたのディレクトリの内容の全て――ワーキングツリーと、index の状態の両方を含む――を取り込み、それらのための blob を Git のリポジトリ中に作成する。tree はそれらの blob を保持し、そして stash コミットはワーキングツリーと index と、あなたが stash をした時の時刻を記録する。
これは良いプラクティスだ。なぜなら、次の日にあなたは git stash apply を使って stash から変更を戻すことになるが、毎日の終わりにはあなたが stash した全ての変更が reflog に存在するからだ。以下は、次の日の朝に作業をするために戻ってきたあと、あなたがやるはずのことだ (WIP はここでは "Work in progress=進行中" を表す):
$ git stash list stash@{0}: WIP on master: 5f1bc85... Initial commit $ git reflog show stash # 上と同じ出力+stash コミットのハッシュ ID 2add13e... stash@{0}: WIP on master: 5f1bc85... Initial commit $ git stash applystash されたワーキングツリーはコミットとして保管されているのだから、他のブランチと似たような扱いができる――いつでも! これは、log を見れたり、いつ stash したかを見れたり、過去に stash した瞬間のどんなワーキングツリーもチェックアウトできることを意味する:
$ git stash list stash@{0}: WIP on master: 73ab4c1... Initial commit ... stash@{32}: WIP on master: 5f1bc85... Initial commit $ git log stash@{32} # これはいつやった? $ git show stash@{32} # 私がやっていたことを見せろ $ git checkout -b temp stash@{32} # 古いワーキングツリーを見てみよう!この最後のコマンドは特に強力だ。見よ、私は今、一ヶ月以上前のコミットされていなかったワーキングツリーをいじっている。私は index にさえそれらのファイルを追加しなかった。私はただ、毎日ログアウトする前に git stash を呼び (stash できるようなワーキングツリー内の変更が実際にあったならば、だが)、そして戻ってログインした時に git stash apply を使うというシンプルな手段を使っただけだ。
stash のリストを綺麗にしたいなら――最後の30日間の分だけを維持したいとしたら――git stash clear を使わないように。代わりに git reflog expire コマンドを使おう:
$ git stash clear # やってはダメ! 全ての履歴を失ってしまう $ git reflog expire --expire=30.days refs/stash <維持されていた分の stash 履歴が出力される>
stash の美しいところは、あなたの作業プロセス自体に控えめなバージョン管理を適用させてくれるということだ。すなわち、ワーキングツリーに対する時間的な階層を持ったステージングと言えるだろう。もしやりたいなら、以下のスナップショットスクリプトのようなものを使って、定期的に stash を実行するようにさえできる:
$ cat <<EOF > /usr/local/bin/git-snapshot #!/bin/sh git stash && git stash apply EOF $ chmod +x $_ $ git snapshotgit reflog expire コマンドを毎週か毎月に設定するとともに、cron ジョブを使って毎時間これを走らせない理由は、もはやないだろう。
7. まとめ
過去数年、私は多くのバージョン管理システム、そして多くのバックアップ機構を使ってきた。それらは全て、過去のファイルの内容を検索する機能を持っていた。それらの大分部は、ファイルが時間が経つに連れてどう変わっていったかを見せてくれる方法を持っていた。多くが、時間を巻き戻すこと、開発ラインを分岐させ、その後そこでやった新しい作業を最新の場所に取り込むこと、などを許してくれた。一部の物は、そのプロセスに対してキメ細かいコントロールを提供し、あなたの作業を修正させてくれ、どのようにでも、あなたがベストと感じる成果物を公開させてくれた。Git はこれらの全てをあなたにさせてくれる。しかもそれらより比較的簡単に――あなたが一旦その基礎を理解したのなら。
Git はこの種のパワーを持つ唯一のシステムではないし、そのコンセプトのための最高のインターフェースが全体に渡って用いられているわけでもない。そうであるにしても、Git が持っているものは、その上で作業するための確固とした基盤だ。将来、Git が許す柔軟性を利用する多くの新しい方法が考案されると私は想像する。私が使ってきた他のシステムの大部分が、概念的な停滞期へ到達していたと私は思う――他のシステムはこの先、私が以前見てきたような物をゆっくり洗練させていくだけだろう。だが、Git には反対の印象を受ける。その見かけによらずシンプルなデザイン上の誓約がもたらす可能性を、まだまだ見せきれていないと、私は感じる。
THE END
8. 参考文献
Git を学ぶ好奇心がそそられたなら、以下の記事をチェックしてみよう:
• A tour of Git: the basics
http://cworth.org/hgbook-git/tour/
• Manage source code using Git
http://www.ibm.com/developerworks/linux/library/l-git/
• A tutorial introduction to git
http://www.kernel.org/pub/software/scm/git/docs/tutorial.html
• GitFaq — GitWiki
http://git.or.cz/gitwiki/GitFaq
• A git core tutorial for developers
http://www.kernel.org/pub/software/scm/git/docs/gitcore-tutorial.html
• git for the confused
http://www.gelato.unsw.edu.au/archives/git/0512/13748.html
• The Thing About Git
http://tomayko.com/writings/the-thing-about-git
Gitに関する翻訳記事はこちらもどうぞ:
・A successful Git branching model を翻訳しました
・【翻訳】あなたの知らないGit Tips
この記事にインスパイアされて記事を一本書きました。
返信削除- Gitレポジトリの内部構造をGraphvizで描画してみた https://qiita.com/kazurayam/items/deea847acaa043a52e36